summary:
for the detection of chemical fiber appearance defects, a semantic segmentation method based on deep learning was used, and the typical semantic segmentation method based on deep learning since 2014 was summarized, and on this basis, it was applied to chemical fiber appearance inspection projects and achieved good results.
into hanchine-月博登录中心入口
as a raw material for textile manufacturing, chemical fiber will be rolled up to form silk cakes before entering downstream textile enterprises by chemical fiber manufacturers, but there will be varying degrees of damage in the production of silk cakes, such as oil stains, wool, stubble, broken wires, etc. defects, these defects will directly cause the low quality of products produced by downstream textile enterprises. oil stains will affect the appearance and coloring of the fabric; the wool will reduce the weaving efficiency and cause defects on the surface of the fabric; the trip wire will not only affect the appearance of the chemical fiber packaging, but also easily cause broken ends and hairs in the subsequent processing of the chemical fiber; silk directly leads to the discontinuity of chemical fibers. therefore, it is necessary to detect surface defects that affect the quality of the chemical fiber cake to ensure the quality of the chemical fiber. at present, most manufacturers use manual inspection of chemical fiber appearance defects, which is time-consuming and laborious and cannot guarantee quality. the use of machine vision to replace manual inspection is an urgent need for chemical fiber manufacturers.
the appearance defects of chemical fibers mainly include oil stains, flicks, broken paper tubes, trip wires, hairs, broken wires, etc. some typical defects are shown in figure 1. most of these defects are performed by semantic segmentation. semantic segmentation combines the two technologies of image segmentation and target recognition. it divides the image into several groups of regions with specific semantic categories, which is a dense classification problem at the pixel level. in the early days, histogram thresholding, hybrid feature space clustering, region growing, and svm-based methods were generally used for semantic segmentation of image objects. these methods are greatly affected by defects and the image itself, leading to more serious missed and false detections. for example, the use of histogram thresholding in the detection of oil stains can easily lead to missed detection of lighter oil stains and false detection of silk thread texture as oil stains.

figure 1. typical defects of chemical fiber appearance
since the concept of deep learning was proposed in 2006, it has achieved remarkable development due to its excellent performance in basic fields such as image classification and detection. especially in 2012, alex krizhevsky and others designed the alexnet model to take the lead in the imagenet image classification challenge. the second place, the traditional method of 10% accuracy, won the championship, which made deep learning attract widespread attention. since then, many computer vision problems including semantic segmentation have begun to use deep learning algorithms, and the recognition accuracy even exceeds the manual recognition accuracy in some areas. semantic segmentation based on deep learning generally includes decoder-based methods, information fusion-based methods, recurrent neural network (rnn)-based methods, and confrontation generation network-based methods.
2.1 decoder-based approach
in 2014, shelhamer et al. proposed a semantic segmentation method based on full convolutional neural network (fcn). as the first of image semantic segmentation, fcn achieves pixel-level classification and provides an important foundation for subsequent use of cnn as a basic image semantic segmentation model. as shown in figure 2, it replaces the fully connected layer in cnn with a convolutional layer, and builds a fully convolutional network. after inputting an image of any size, it is learned and processed to produce an output of the corresponding size, and then each pixel is classified this process is called an encoder; after the classification is completed, the classification result is mapped to the original image size through upsampling to obtain dense pixel-level labels, that is, the semantic segmentation result. this part of the process is called a decoder. fcn combines multi-resolution information, upsampling and fusion of feature maps of different sizes, and achieves a more accurate segmentation effect.
however, when the fcn is up-sampling in the decoding stage, it is easy to lose the position information of the pixels and affect the segmentation accuracy. how to design the decoder ingeniously is very important to the segmentation result. for example, in 2017, the segnet algorithm proposed by badrinarayanan et al., each code of segnet each layer corresponds to a decoder layer. the output of the decoder is sent to the classifier to independently generate class probabilities for each pixel. the spatial position in the feature map can be accurately reverse-mapped to its initial position, which is more accurate than fcn. image boundary information, better segmentation effect.
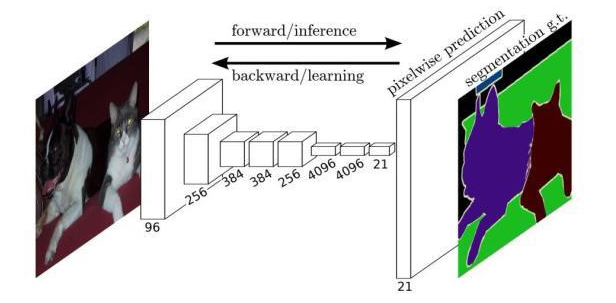
figure 2. fully convolutional neural network (fcn) semantic segmentation model structure
2.2 method based on information fusion
in order to make the semantic segmentation effect better, make full use of the spatial information of the segmentation target, and then fuse different levels of information, generally there are the following information fusion methods: pixel-level feature fusion, multi-feature map and multi-scale fusion.
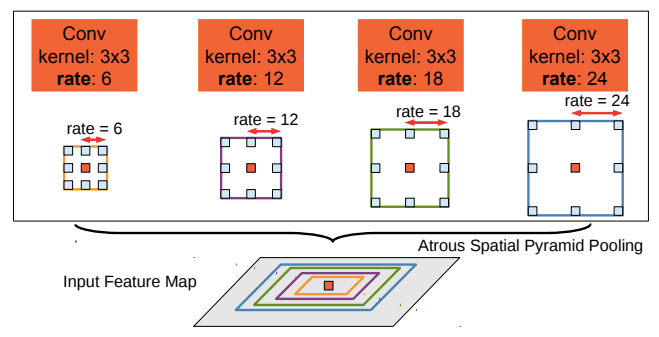
figure 3. the pyramid hole pooling (aspp) module
in the pixel-level feature fusion method, for example, in 2014, chen lc of the google research team proposed the deeplab v1 model, which introduced a conditional random field (crf) as a post-processing module, and combined each pixel in the image with one of the crf models. one-to-one correspondence between each node, measures the connection between any pixels, realizes the fusion of the underlying image information pixels, and realizes the enhancement of segmentation details; in 2016, deeplab v2 introduced pyramid hole pooling (aspp) on the basis of deeplab v1 module, select the perforated convolution processing feature maps with different sampling rates to improve the segmentation accuracy; in 2017, deeplab v3 continued to optimize the aspp structure on the basis of deeplab v2. by cascading multiple hollow convolution structures, it effectively extracted expressive features; in 2018, deeplab v3 uses deeplabv3 as an encoder, and the backbone network uses the xception model to improve the robustness and operating speed of semantic segmentation.
in the multi-feature map and multi-scale fusion method, for example, in 2015, liu w et al. proposed a pyramid scene analysis network (parsenet) to convert the global feature map into the same size as the local feature map, and different types of processing modules focus on different regions of activation the feature maps of, after merging, are input to the next layer or used to learn the classifier, effectively using the context information provided by the previous layer, and achieving a better segmentation effect than the fcn jump structure. in 2020, ho kei cheng et al. proposed cascadepsp, which uses an image and multiple imperfect segmentation masks of different scales to generate refined segmentation. multi-scale input enables the model to capture different levels of structure and boundary information, and adaptively merge it. with different mask characteristics, all low-resolution input segments are bilinearly upsampled to the same size and connected with rgb images; cascadepsp is a general cascade segmentation refinement model, which can refine any given input segmentation, improve the performance of existing segmentation models without fine-tuning.
2.3 method based on recurrent neural network
recurrent neural network (rnn) is a memory-based network model that learns long-term dependencies and maintains memory from continuous data. it has periodic connections and captures by modeling long-term semantic dependencies of images the ability of context in images is successfully applied to semantic segmentation. for example, in 2015, visin f proposed reseg semantic segmentation based on renet for image classification. each renet layer in this model consists of 4 rnns (horizontal and vertical scanning images), which encode activation information or tiles and generate corresponding for global features, the renet layer is stacked on a pre-trained convolution structure to generate general local features, and segmentation maps are obtained through global features and local feature upsampling.
2.4 method based on confrontation generation network
in 2016, pauline luc et al. applied the adversarial generation network (gan) to semantic segmentation for the first time in the document "semantic segmentation using adversarial networks". they used a discriminator to identify real labels and segmented images, and reduced the high order between labels and segmented images. inconsistency. the network model consists of a segmenter (common segmentation network model) as the generator, and then adds a discriminative network structure, through gan to produce high-quality generated images to improve pixel classification, the method segmentation effect is general, it is against the generation network (gan) is an effective attempt to apply to semantic segmentation. subsequent semi-supervised semantic segmentation based on adversarial generative networks has developed, such as the 2017 "an adversarial regularisation for semi-supervised training of structured output neural networks".
hanchine analyzed the oil stains, flicks and paper tube damage in the appearance of chemical fiber defects, and used deep learning semantic segmentation methods to deal with the extremely unbalanced positive and negative defect samples, and designed the use of this project loss function, while analyzing the characteristics of oil pollution, flicking and paper tube damage, the defect has been better segmented, and has been recognized by customers. the specific effect is shown in figure 4.

figure 4. inspection results of chemical fiber appearance defects